Alibaba/Druid 无限次重试报错并阻塞业务线程
Alibaba/Druid 是一个广受欢迎的开源数据库连接池组件。但是,由于配置不当,也会对服务稳定性产生负面影响。
我们的某个服务提供了一个功能,可以帮助用户随机预览给定数据源上的表数据。但是,当用户提供了错误的IP/Port信息,或者错误的授权信息,或者错误的数据库协议的时候,服务接口未能及时响应,最后网关报504超时,影响用户体验。
查看日志
为了优化这个环节,我们先查看了应用的异常日志,发现应用仍然在不断的抛出连接失败的异常,并且,抛出异常的线程不是HTTP Worker线程,而是名为Druid-ConnectionPool-Create-XXX的线程。详细如下:
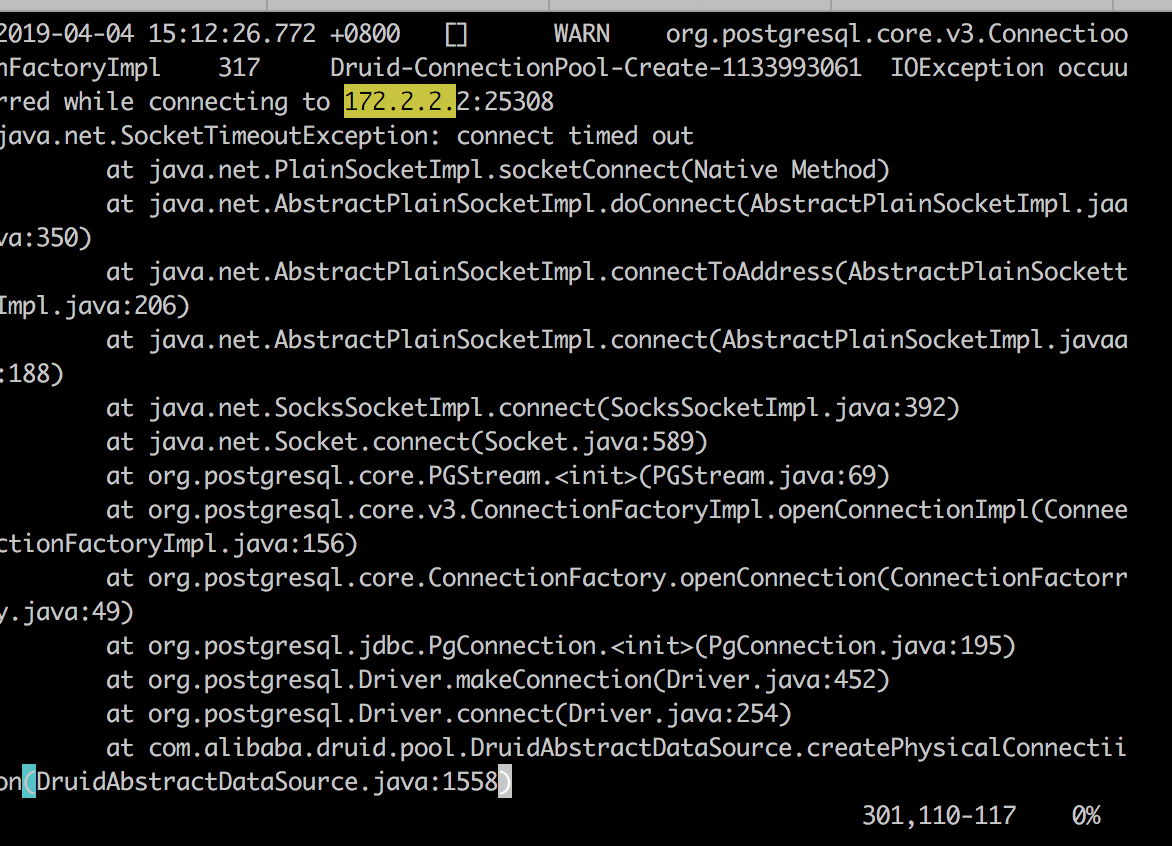
其实后面还有两行,只是当时没有截出来:
1 | at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1623) |
看来问题是出在 CreateConnectionThread.run 这个方法上,估计应该是没有正确的配置重试/熔断策略,以至于Druid无限重连并且在日志中抛出异常。接着,翻开了 DruidDataSource 的代码,并且定位到 run 代码(简化):
1 | for (;;) { |
大致的代码流程:
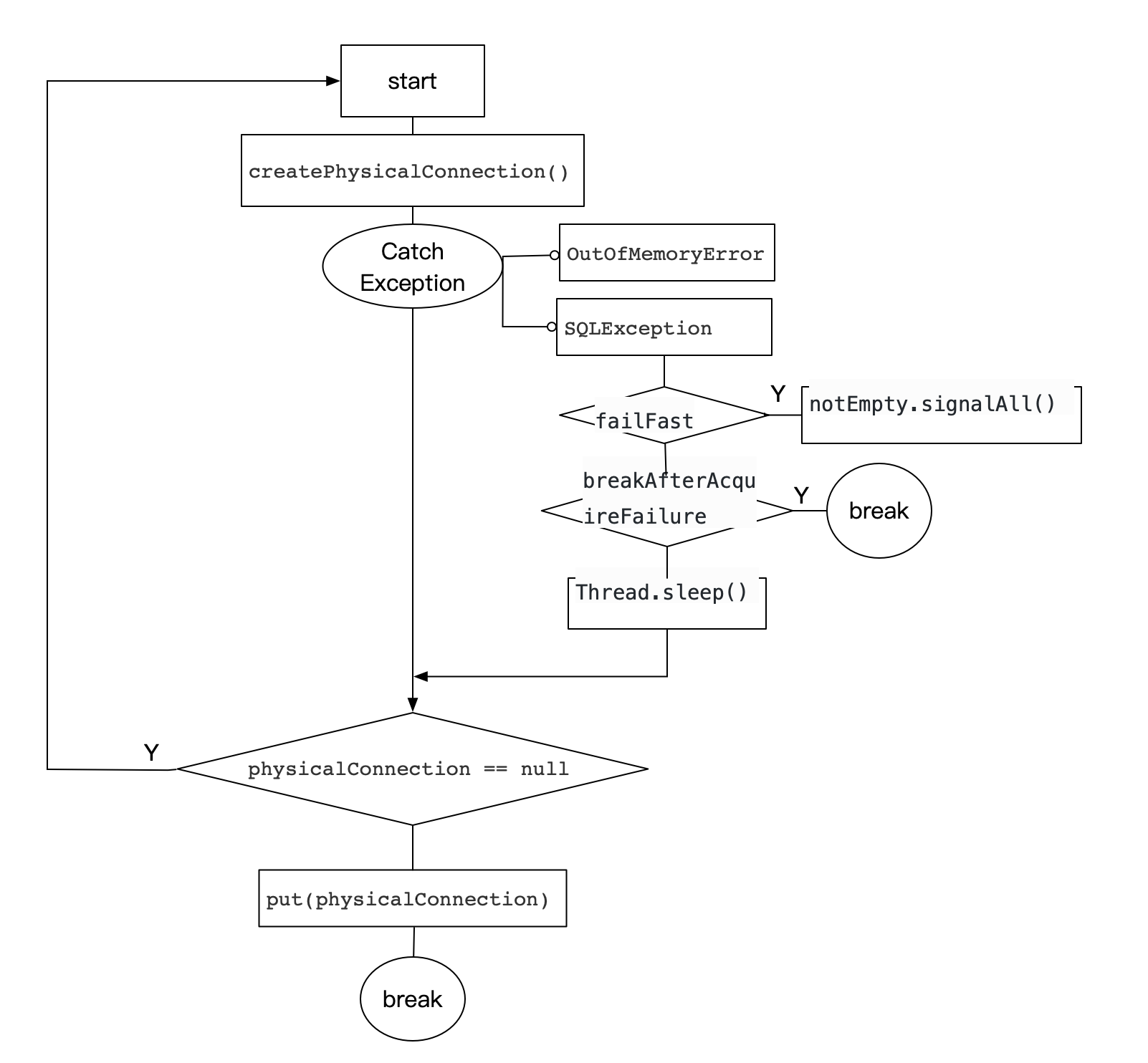
从上面的介绍可以看出,一般只有正确获取到数据库连接或者设置breakAfterAcquireFailure=true才能跳出这个for循环(InterruptedException 不考虑)。但是,从代码中可以看到,breakAfterAcquireFailure的默认值是false,因此要想结束这个,就只有手动设置 breakAfterAcquireFailure=true。后来,从github上也搜索到了一条相关issue,发现大家也遇到了和我一样的问题:无限重连错误。
因此,在代码中加入了设置breakAfterAcquireFailure=true的逻辑,应用日志中果然不再反复抛出同一个异常了。但是,测试过程中发现,问题仍然没有得到完整的解决,服务接口仍然未能及时响应,最后网关还是会报504超时错误,这里面还有我们没考虑到的地方。
使用Jstack调试
由于服务接口一直都没能及时返回响应,因此很直观的一个思路就是希望可以看看这个HTTP Worker线程在做什么,这时候Jstack命令就可以派上用场了。
通过jstack命令,发现http线程停留在drui库的takelast调用里,被阻塞住了。后来打开代码查看才知道,原来线程是在等待 notEmpty.await() 调用返回。从代码追踪可以知道,notEmpty是一个条件变量,druid线程中直接break循环是不会触发notEmpty的signalAll()方法,因此http线程也无法从条件变量中唤醒运行,因此接口就会一直无法提供响应。并且,随着调用次数的增多,越来越多的线程陷入阻塞状态,最终将没有线程资源可以提供服务。
因此,又在代码中加入了设置failFast=true的逻辑,这样http线程就可以在重试多次失败以后迅速被唤醒,及时返回错误信息,并且继续提供服务。至此,没有无限重连报错,线程也不再阻塞,问题得到彻底解决。
总结
出现问题的时候大胆假设,小心求证,灵活运用基础知识与调试工具,多一些耐心。