用pprof排查CPU Killer
故障背景
最近新上线了一个微服务,主要功能是定期执行各种定时任务,其中一个任务涉及到持有Redis分布式锁,并通过time.Ticker自动续期。(看到这里,也许你已经猜到了问题根源)。
这个服务上线以后,没有出什么大问题,每个任务都按照预期在规定时间内完成。然而,随着时间的推移,任务开始出现超时,甚至有的时候进程已经卡顿到连相关指标监控都无法获取。
初步排查
以下是当时的CPU利用率以及服务刚启动时的对比:
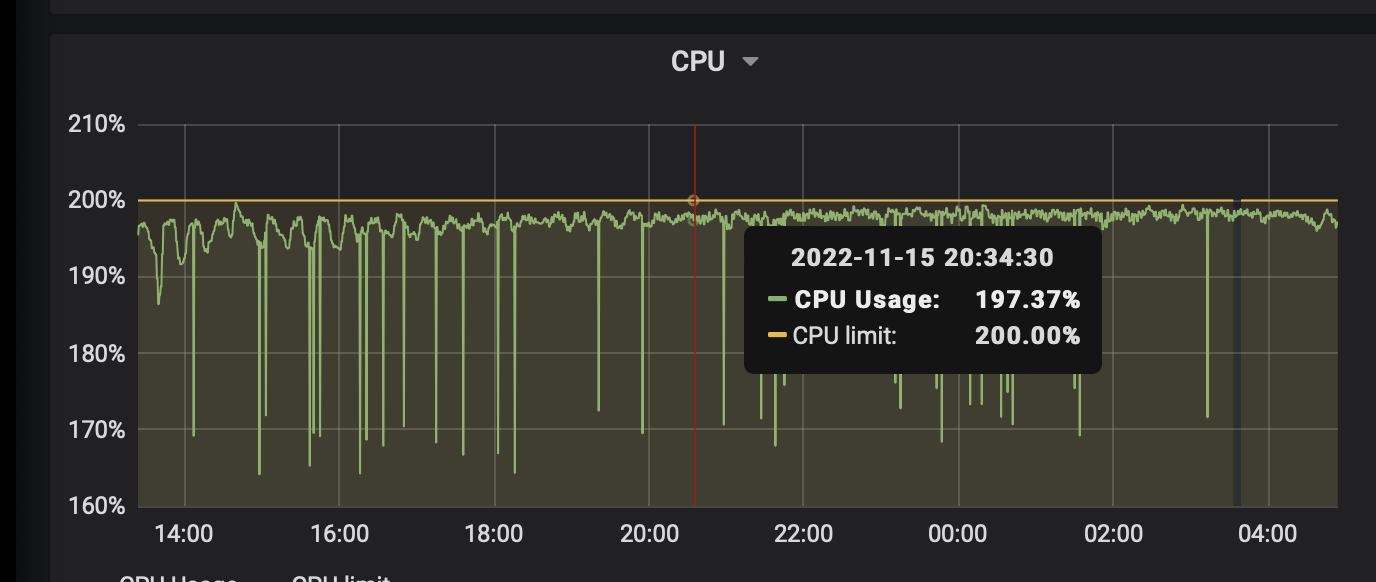
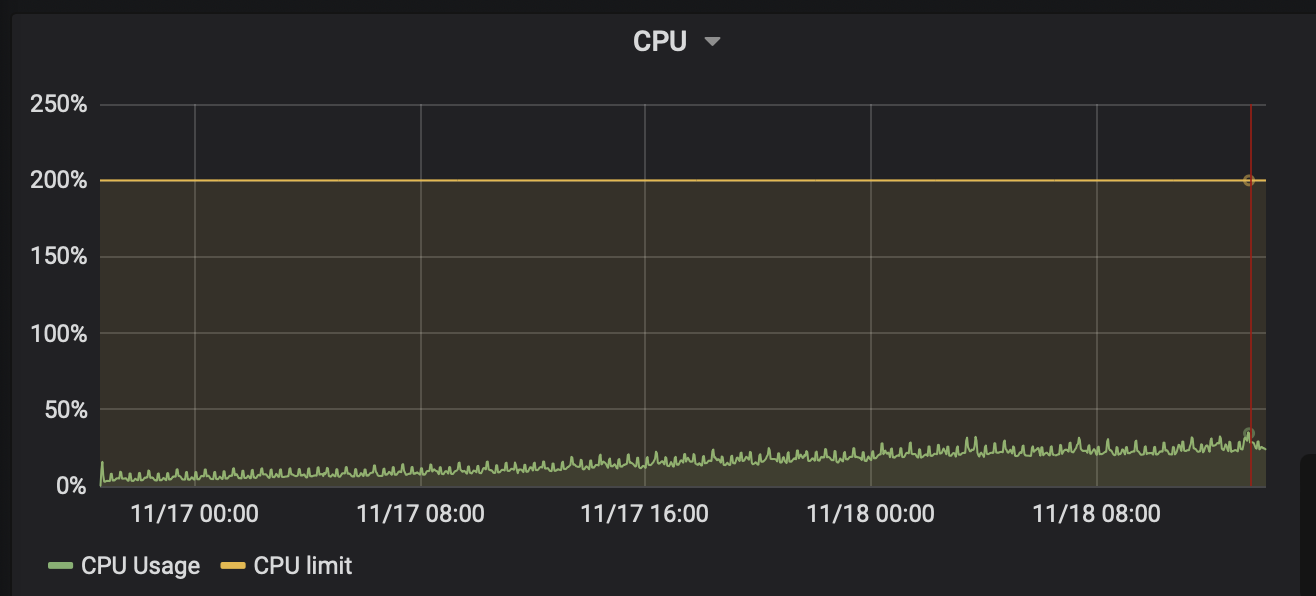
对于这种7*24小时运行的服务CPU利用率上升的情况,猜测的第一种可能性,一般是内存泄露导致GC繁忙消耗CPU资源。可以看到,GC耗时确实很可疑:
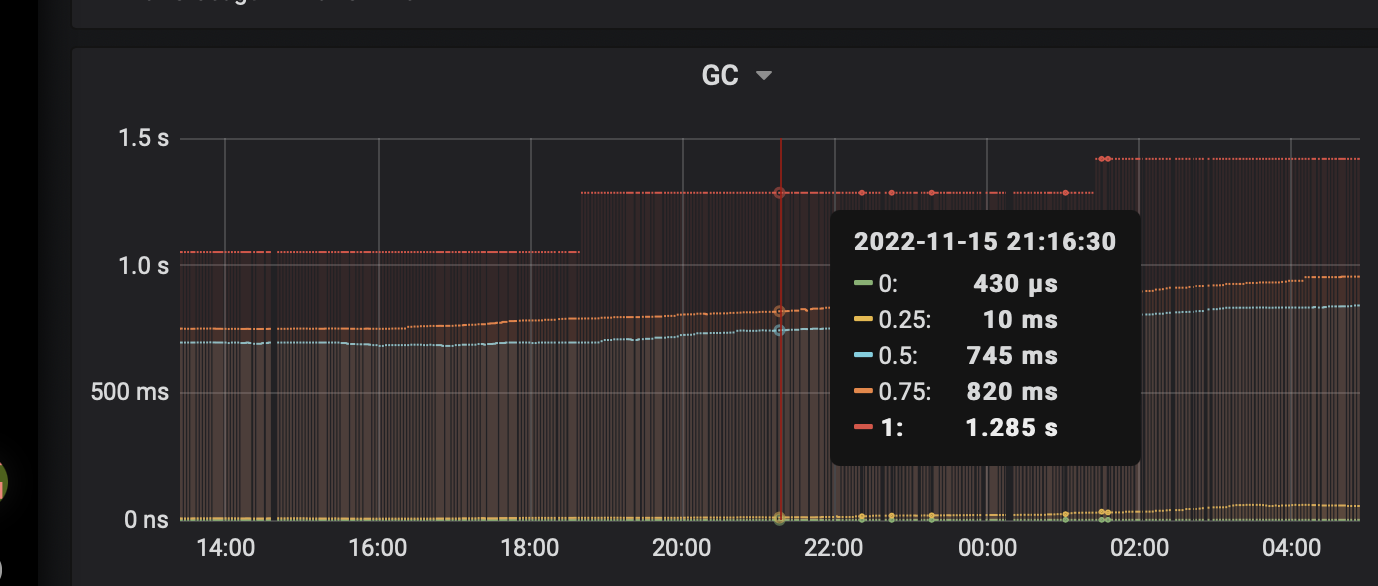
但是,到底是GC占用CPU资源导致进程卡顿,还是进程卡顿导致GC耗时增长呢?
排查内存
这是当时的内存情况:
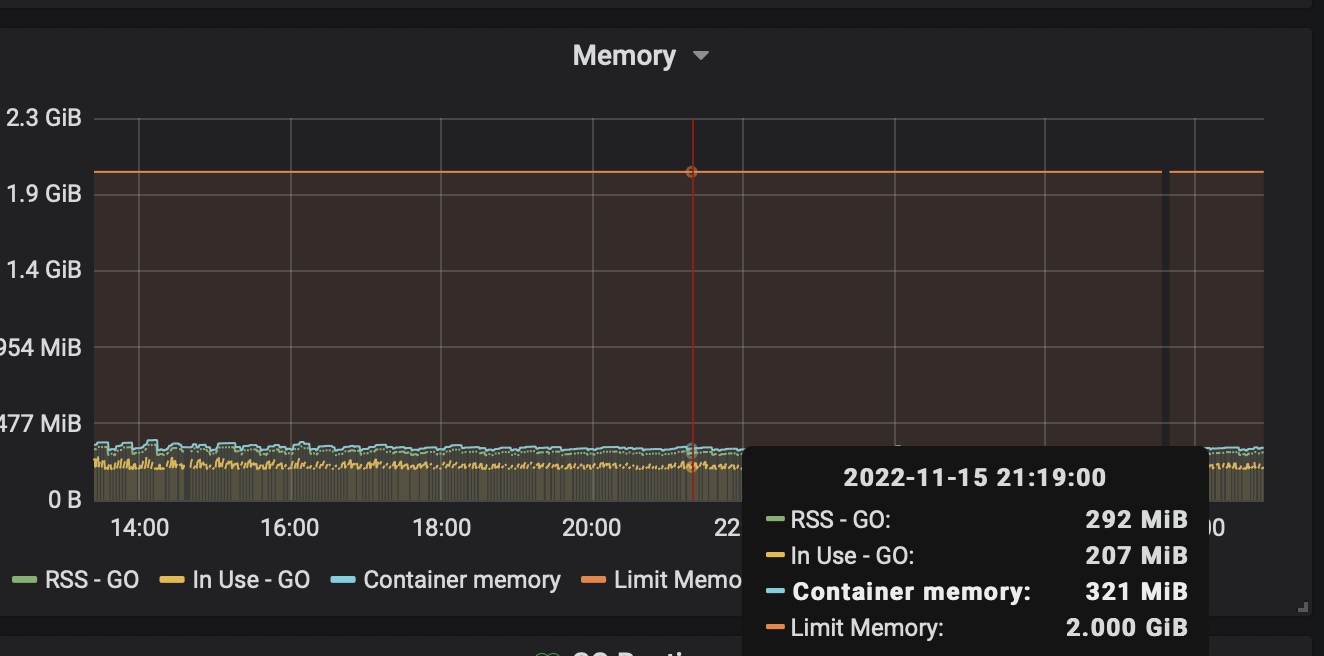
可以看到,容器内存才300MB,这么点内存会导致GC耗时一秒多?很显然,这种可能极低,GC本身的耗时和CPU资源应该很低才对,问题出在别的方面。
接着,我们对比了一下进程刚启动时的内存资源监控信息:
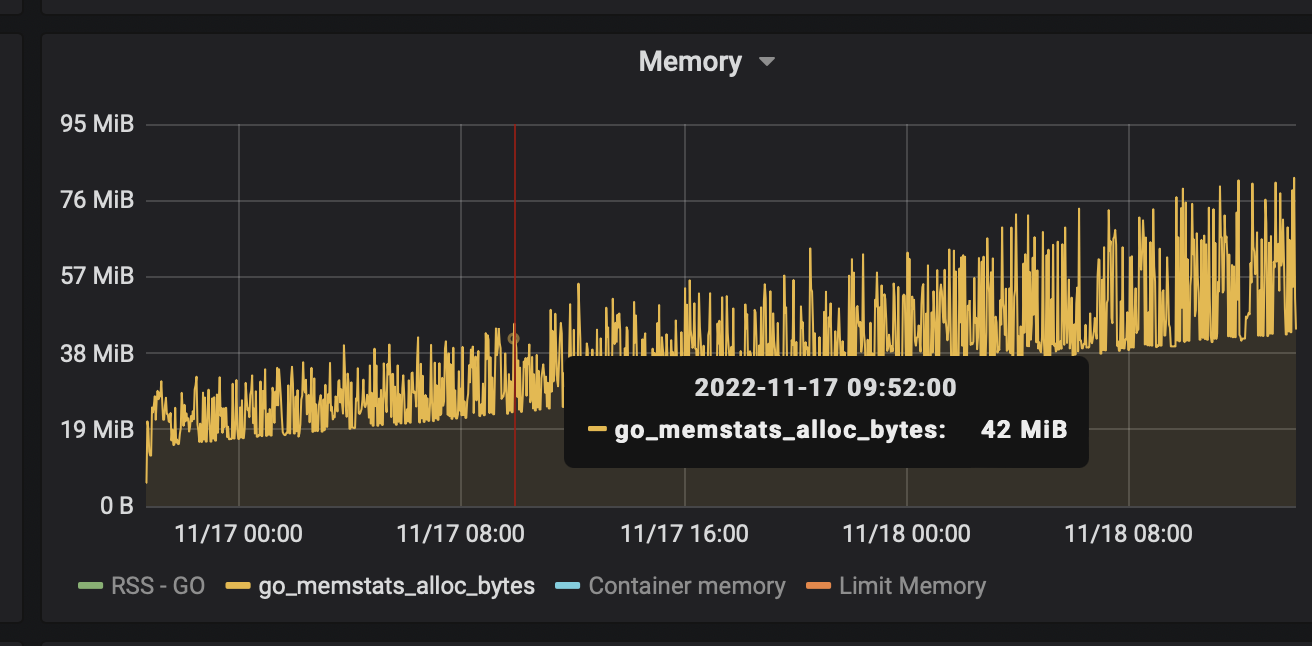
可以得出结论,内存确实存在泄漏的情况,虽然泄漏的好像不多。这种内存占用不多却能耗费大量CPU的场景,我隐隐猜测可能是timer泄漏。
pprof排查
由于这个服务禁用了CGO,因此可以不考虑C库的影响。为了排查具体的CPU killer,我们需要用到golang的性能分析工具包:pprof
pprof可以对CPU profile生成火焰图,精确定位CPU消耗的具体环节:
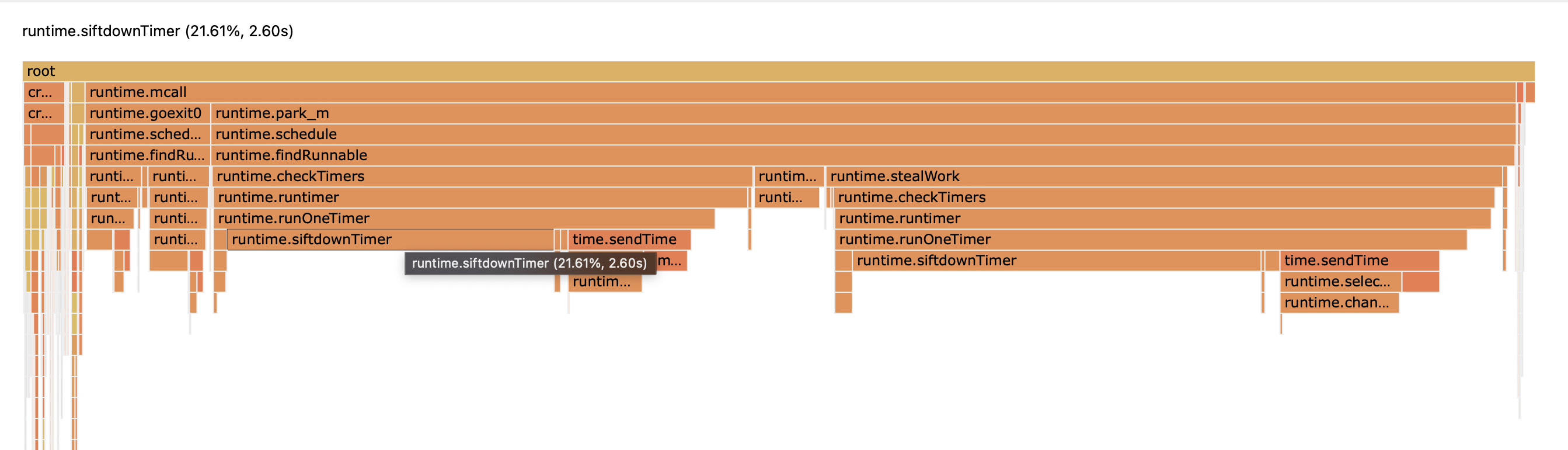
从图中可以看出,左侧的业务逻辑仅占用了极少量CPU时间,大多数时候在忙着runtime.shchedule(GC的占用也微不可见)。
而其中最醒目的就是siftdown timer这个函数了,这个似乎验证了我们的猜测。
剩下一个问题,我们需要确定确实timer存在泄漏。通过pprof工具,我们对heap进行采样,确认了timer对象占用的内存在增长:
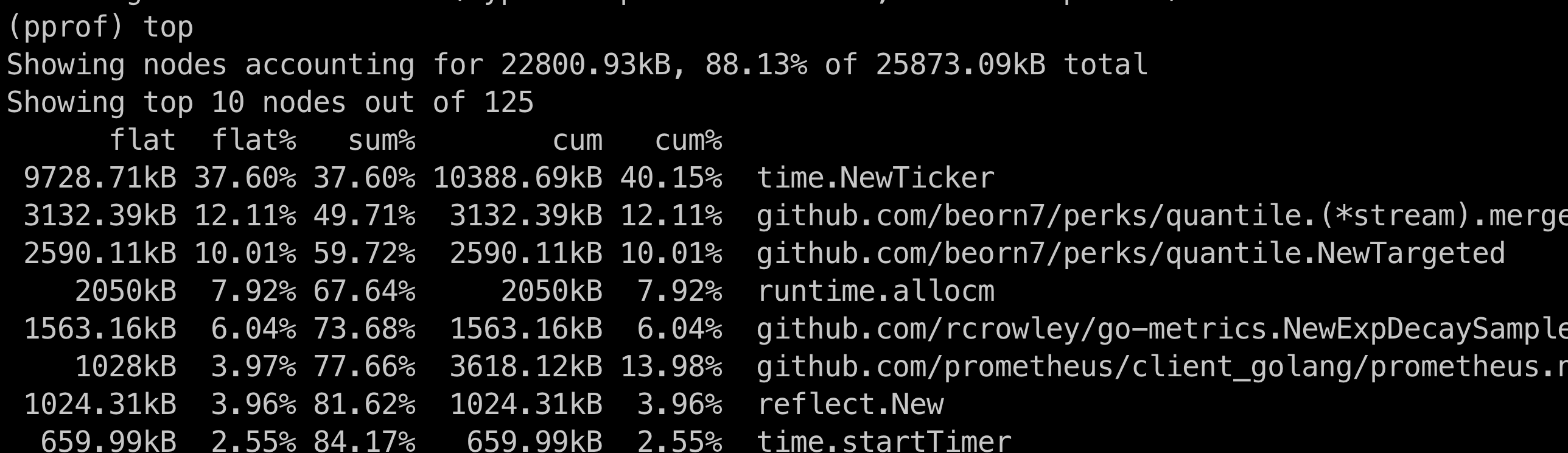
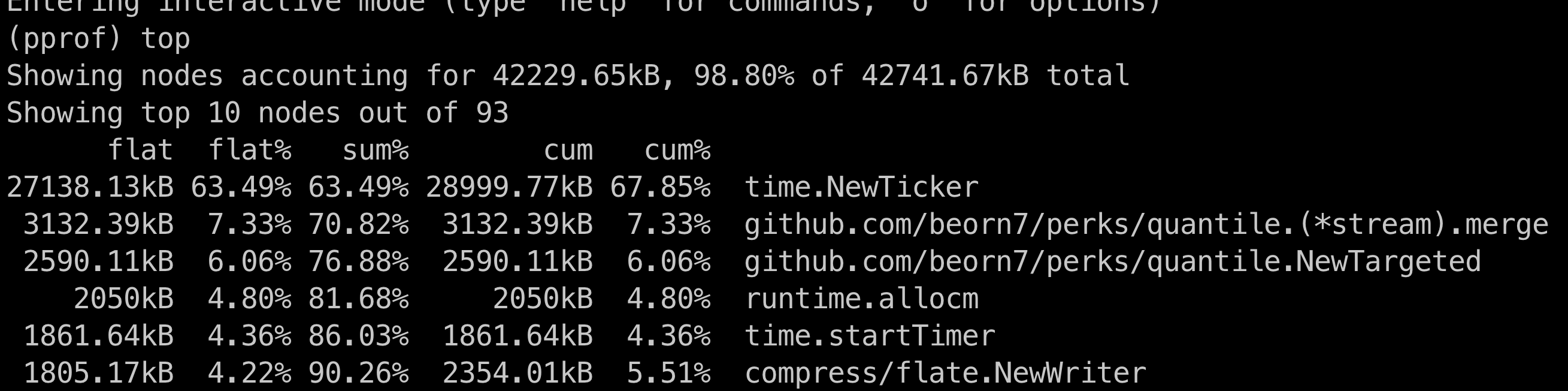
通过tree命令非常顺利的就找到了泄漏的源头,是time.Ticker没有及时stop导致。涉及具体代码就不贴图了^_^
最后,代码提交Review,上线,经过两天的验证,问题得以修复~