Gossip协议是一个在大规模分布式系统中被广泛使用的信息交换协议,用于解决应用层的多播问题。
最近在学习Cousera上的Cloud-Computing-Concepts课程,里面布置了一套基于Gossip的成员协议的编程题,花了一天时间写完代码与调试,记录一下读后感与体会。
Gossip 理论
如何在一个大规模分布系统中高效传播一个信息?
最简单的办法是向集群中的每个节点发送一条消息,但是随着系统规模的增大,考虑到网络的丢包与延迟以及防火墙之类的特殊构造,这个方法不能确保每个节点都能得到最新消息,源节点的传播耗时与网络负载也过高。
另一个做法是维护一个树状网络拓扑图,每个节点向它的子节点传播信息,并且通过ACK/NACK确认消息,这个方案降低了节点的耗时与负载,但是为了处理节点失败的场景,需要对网络拓扑做非常复杂的维护。
还有一个办法,那就是每个节点随机选择b个其他节点进行信息交换,最终这个消息就传播到了整个网络!这就是Gossip协议,它就像现实生活中的谣言一般,一传十,十传百,最后全世界都知道了。
Gossip 实现
Gossip协议有三种工作方式:Push,Pull 以及 Push/Pull混合。
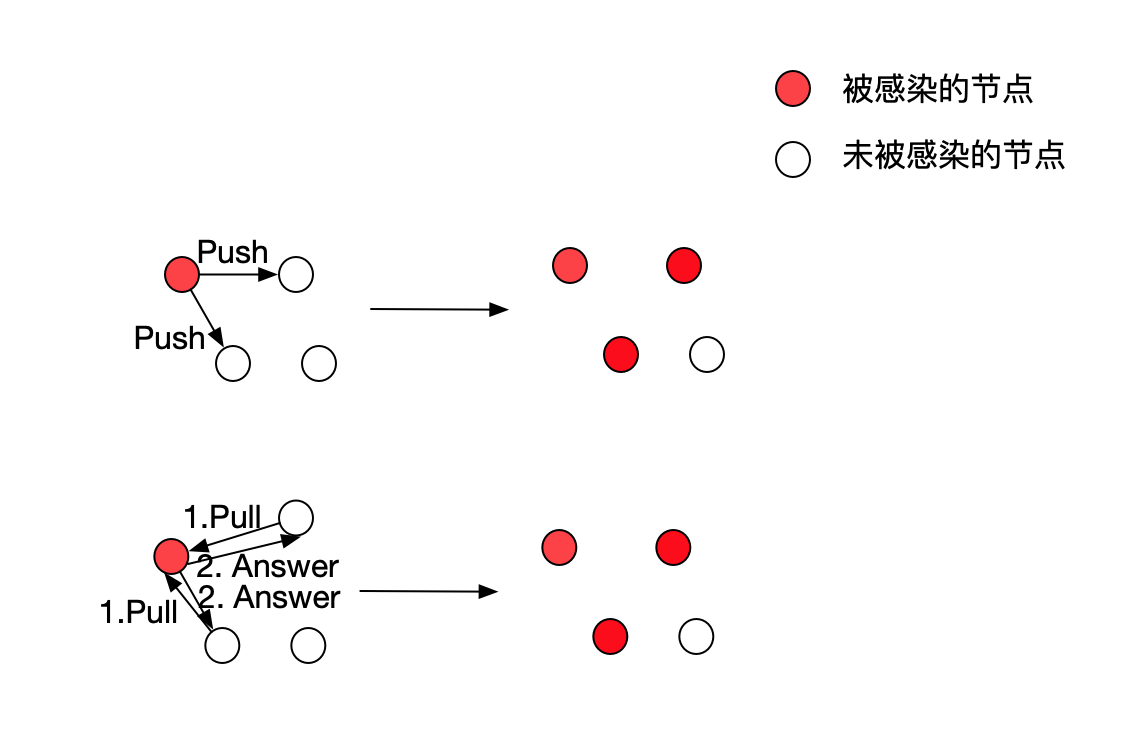
Push方式:
- 某个节点x随机选择b个其他节点作为目标
- x向每个目标节点传输消息
- 其他节点收到消息后,根据消息的时效性更新本地消息
Pull方式:
- 某个节点x随机选择b个其他节点作为目标,向每个目标节点询问最新消息
- 目标节点向x返回最新消息
- x收到回复后,根据消息的时效性更新本地消息
这两种方式可以用如下简图表示:
基于Gossip 协议的成员协议
这是Cousera课程上的一道编程作业题:membership-protocol,作业源码参见:成员协议作业
这个成员协议的实现不需要考虑网络传输层,并且提供一个入口函数:nodeStart,用于将节点加入成员组,成员组中的每个成员都运行着相同的协议。为了简单起见,我实现的Gossip协议是Push方式,成员协议主要分为如下几个部分:
- Gossip:定期心跳与状态推送
- Gossip:消息更新
- 清理节点
- RPC消息的编解码器
流程简图如下:
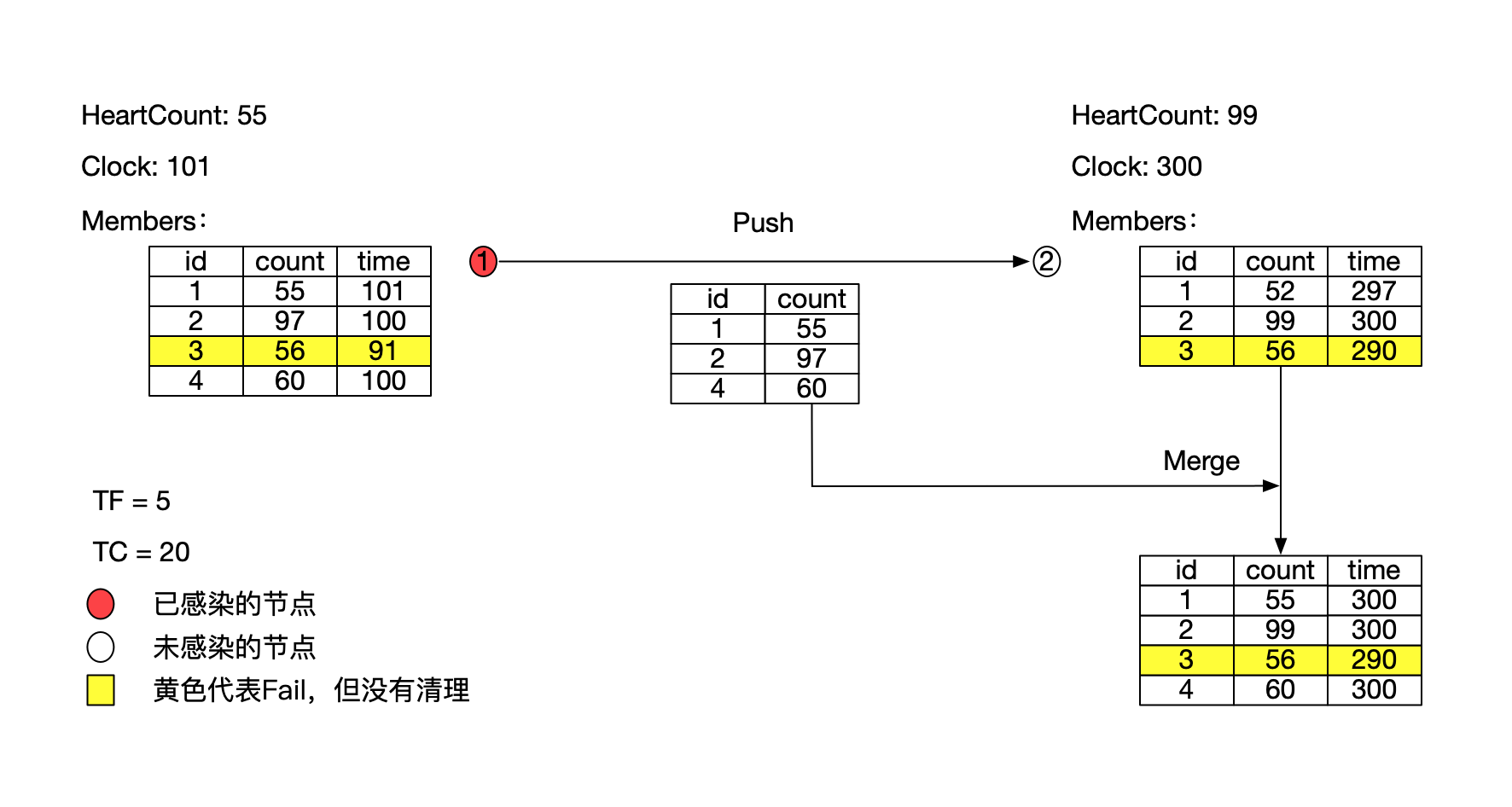
协议状态与术语
每个节点在本地都维护如下信息:
- 当前心跳计数(自增)
- 集群成员列表(心跳计数器与上一次更新的本地时间)
健康节点:心跳计数器的更新时间与本地时间相差不超过某个常量TF(Time of Failure)
可移除节点:心跳计数器的更新时间与本地时间相差超过某个常量TC(Time of Cleanup)
失败节点:心跳计数器的更新时间与本地时间相差超过某个常量TF,但是不超过常量TC
心跳与状态推送
协议每隔一个单位时间周期T,都会执行一些定时任务,包括:心跳与状态推送。
心跳指的是自增心跳计数器,并推送给目标节点。
状态推送指的是协议会整理本地成员列表,将其中健康节点的信息推送给目标节点。
通常心跳与状态信息都是一起推送的,减少发包次数。
消息更新
节点收到消息后,将消息中包含的成员列表信息与本地成员列表进行比对,如果消息中成员的心跳计数大于本地成员的心跳,说明丢包了,更新本地成员的心跳计数和时间戳;如果消息中成员信息不在本地成员列表中,说明这是一个新加入的节点,将其加入本地成员列表并设置时间戳
清理节点
清理节点指的是移除成员列表中心跳计数器的更新时间与当前时间相差超过某个常量TC的节点,定期执行。
消息编解码
由于消息比较简单,只是简单的心跳+状态,因此编解码也相对简单,不需要特殊的格式。
Trick
这里面有一个Trick,TC与TF应该设置多大合适?
一般TF指的是预计最大网络延迟,如果更新时间相差超过TF,心跳没有得到更新的原因很大可能是节点已经Fail了,而不是网络延迟。TC一般设置为3 * TF以上,推论如下:
- 假设节点A在T0时刻收到节点B的心跳
- 到T0+TF-1,恰巧,非常巧,A认为B仍然是健康的,A仍然将B的节点信息推送给第三个节点C
- 到T0+TF时刻,A仍然没有收到B的心跳,A将B标记为Fail
- 到T0+2*TF-1时刻,A的消息才恰好到达节点C,C更新B的心跳信息
- 到T0+3*TF-1时刻,C才将B标记为Fail
- 到T0+3*TF时刻,此时A将节点B移除才是安全的,因为此时考虑到网络延迟,集群中的所有成员(C)都知道节点B处于Fail状态,并且不会扩散它的心跳了。
那么,如果TC小于3*TF,也就是如果在T0+3*TF时刻以前就删除节点B,会发生什么呢?由上述分析可知,直到T0+3*TF-1时刻,C才将B标记为Fail,在此之前C传播的消息中是有可能带有B节点的信息的!因此如果A过早将B节点移除,A后续收到C的消息以后又会重新将B节点加回成员列表,同样也会导致C将B节点移除以后,收到A的消息继续将B节点加回成员列表。这样就像乒乓球一样互相影响,使得失败节点B永远都无法被清除。
总结
Gossip 协议是一个分布式系统中应用比较广泛的协议,可以用于失败检测,动态负载均衡,弹性扩展等需要共享信息的地方都可以用到它。与此同时,Gossip协议也会传播大量的信息,因此实际应用过程中还是需要进行进一步的改进。