Xapian 读优化
说一下本文的背景.
我们曾经用Xapian作为内部的倒排索引(只读),在流量比较高的情况下,调用方感知延迟上升,需要对倒排服务进行性能优化.
关于调用方延迟的影响因素
在我们的服务场景里,暂时还没到网卡影响性能的程度,网络协议也没有成为瓶颈,因此调用方观察到的延迟主要还是发生在服务端.
现在的后端服务都是比较成熟的框架,通常会有Accept线程(listen and accept), IO线程(读写request/response,可能还包括编解码),Worker线程(也叫CPU线程,实际干活的).
不同线程间通常是通过队列交换消息,比如Acceptor线程将建立的连接分给IO线程处理IO事件, IO线程将完整解码请求入队等待Worker线程处理, 最终的response也要由队列送回IO线程.
因此,请求的实际服务端延迟通常会受这些因素影响: IO读写编解码, 请求在队列中等待的时间, 实际CPU计算, 所依赖的其他资源, 内部业务的锁竞争.
IO读写编解码, 请求在队列中等待的时间这两项对于Worker是无感知的,一般是在框架中通过观察者模式暴露.
比如fbthrift的 ThreadManager::Observer 和 server::TServerObserver, 就提供了相关事件次数和有关时间.
Worker延迟的影响因素
在Worker处理请求期间, 延迟除了自身的业务逻辑计算(On-CPU),还与等待其他资源, 等待业务锁竞争(这些都算是Off-CPU)相关.
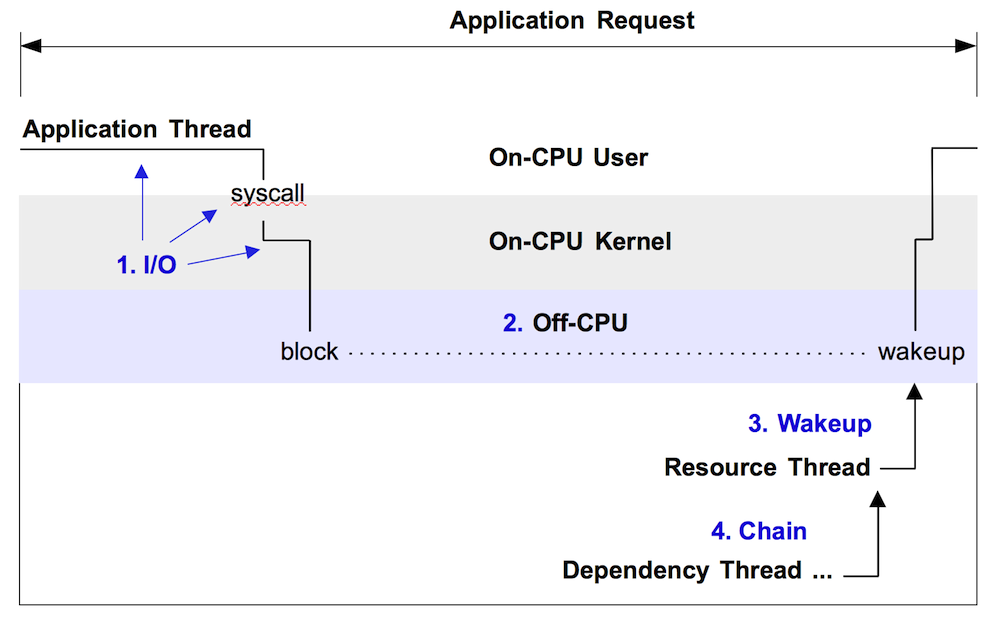
本文所提及的优化就是找出on-cpu的热点部分进行优化.
关于Off-CPU部分其实也可以进一步优化,但是Off-CPU的分析比较困难,容易受IO线程的wait干扰,以后看看有没有实践的机会.
Perf
Linux内核的Perf工具,为我们提供了分析On-CPU热点瓶颈的能力, 见Wiki.
1 | perf record -F99 -g -s -p <pid> |
分析与优化
先上图

分析结论:
很明显,在图中占CPU大头开销的是 GlassPostList::move_forward_in_chunk 和 内核函数 ccopy_user_enhanced_fast_string,
前者是xapian存储引擎中的数据解码逻辑,后者是pread系统调用过程中拷贝数据,看起来两者都是无懈可击?
随着我仔细在图中查看, 我发现CPU的40%时间是花在了 GlassDatabase::get_doclength 上, 这个函数里面也包含了 GlassPostList::move_forward_in_chunk 和 内核函数 ccopy_user_enhanced_fast_string
从 GlassDatabase::get_doclength 的名字上看,似乎用一个简单的内存数组就能解决,从而完全节省出40%的CPU时间!
优化方案:
初始化, 预先计算好doclength数组,并保存在文件里
每个线程以mmap的方式加载,共享内存(xapian坑爹的一点,必须每个线程打开一个db)
修改
GlassDatabase::get_doclength的实现,从mmap数组中返回doclength
优化后的样子:

以及前后的容量,延迟对比:
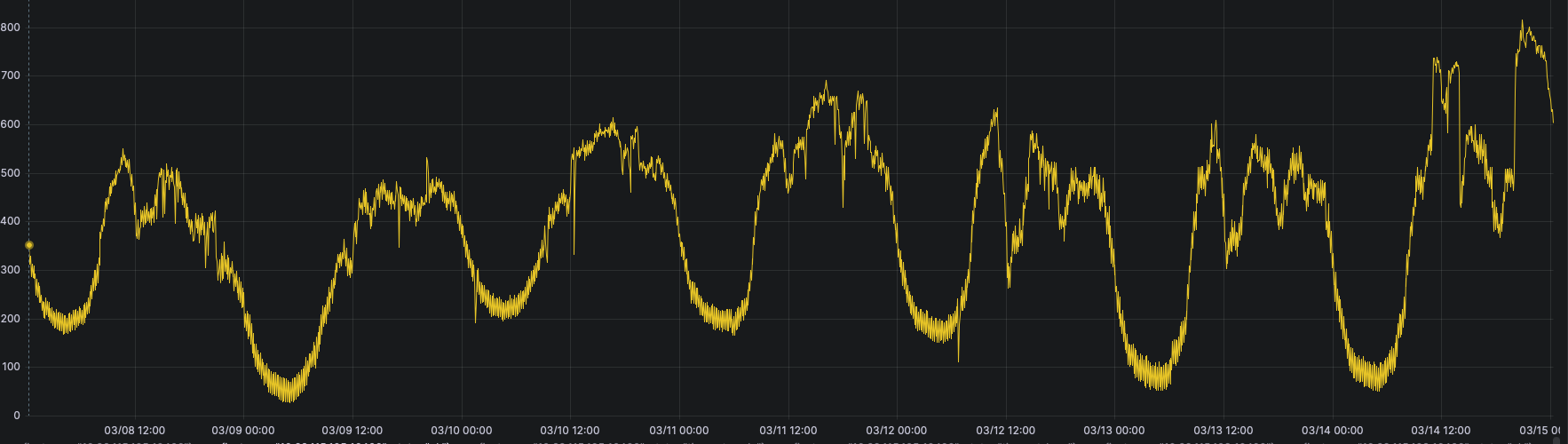
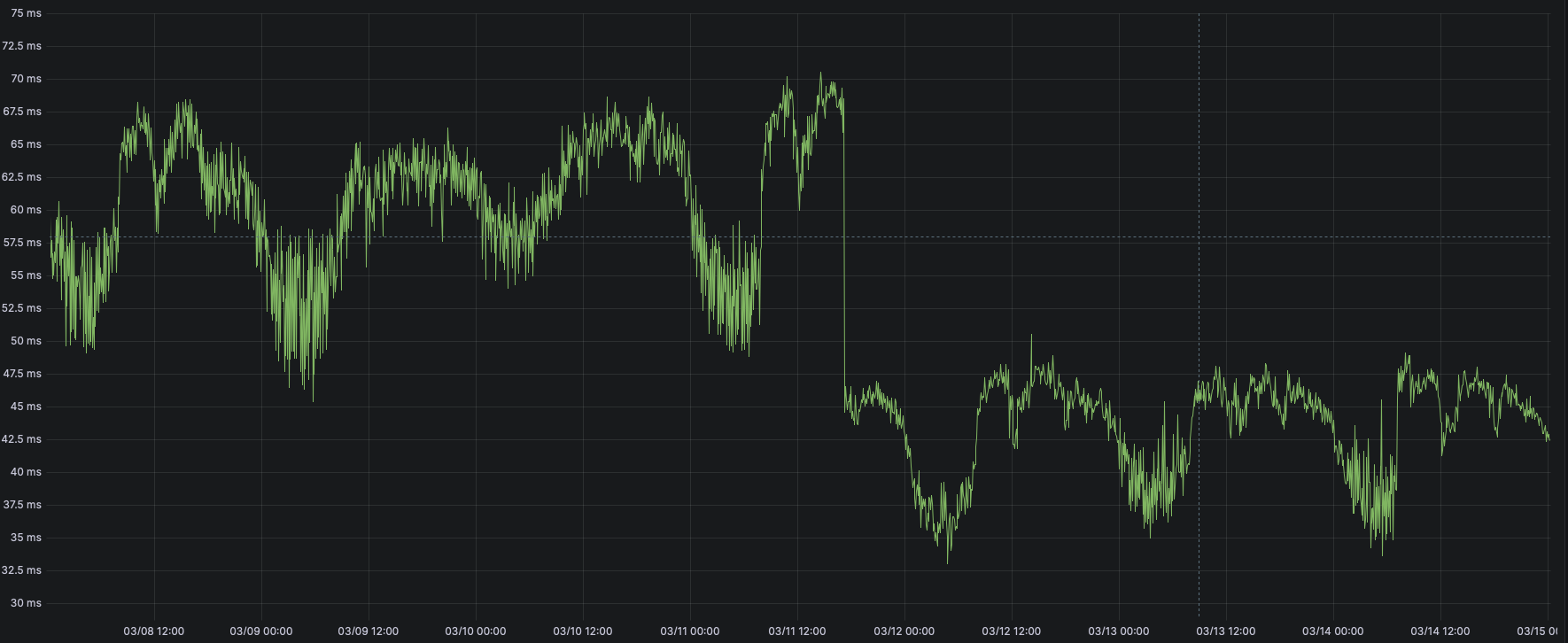
可以很明显的看到:
每秒TPS从500上升到了800, 而延迟反而从62ms下降到48ms(优化前后CPU利用率都在800%上下) ^_^
与此同时,从火焰图上也能看出, GlassDatabase::get_doclength占用时间已经很小了,接近1%
现在的热点是 GlassPostList::skip_to ,这个源头在于xapian的GlassDB存储引擎,后续的优化重点就是设计一个更高效的存储引擎,提升数据解码性能
根据On-CPU时间的定义, 我们可以计算出优化前后的平均On-CPU时间分别是: 8*1000 / 500 = 16ms 和 8 * 1000 / 800 = 10ms, 也就是说这次优化节省了6ms
但实际上, 优化前后的延迟分别是 62ms 和 48ms, 根据公式 avg-latency-ms = off-cpu-ms + cpu-used * 1000ms / TPS
也就是说Off-CPU部分的时间分别是: 62-16 = 46ms 和 48 - 10 = 38ms, 这次优化也节省了8ms的Off-CPU时间, 主要是避免了IO开销
在考虑到优化后IOPS其实是变高了, 实际Off-CPU实际的节省应该会更多一些
总结
对于静态定长索引,其实最优的存储结构就是数组(或者mmap),然后用offset读取就好了,(更近一步可以用cache优化)
从这次的计算中,我们能看出,Off-CPU部分的时间占比太高,这在未来也会是优化的主要重点